

Dans ce didacticiel, je vais vous montrer comment vous pouvez créer un script qui récupère automatiquement les données du sitemap de votre blog et tweete automatiquement les articles de blog sur Twitter. Il existe donc de nombreux services payants qui proposent cette fonctionnalité comme HootSuite. Et si vous pouviez faire la même chose gratuitement ?
Le grattoir Web récupère des données telles que l’URL de l’article, le titre de l’article et la description en une ligne de cet article de blog. La plupart des données que nous pouvons récupérer à partir du plan du site de notre site Web.
Qu’est-ce qu’un sitemap et comment le trouver ?
Laissez-moi vous l’expliquer, un sitemap est une page XML qui stocke toutes vos métadonnées de vos articles de blog. Il stocke des données telles que l’URL des articles publiés, l’heure de la dernière modification et le nombre d’images.
Vous vous demandez peut-être pourquoi nous avons besoin d’un plan du site, n’est-ce pas ?
Le plan du site est nécessaire pour que les moteurs de recherche puissent répertorier vos articles de blog ou toute page publiée sur votre site Web dès que possible. Il existe également d’autres raisons, vous pouvez consulter cet article pour plus d’informations.
Essayons maintenant de trouver le sitemap de votre site Web. Dans la plupart des cas, il s’agit de www.YOUR-WEBSITE.com/sitemap.xml ou www.YOUR-WEBSITE.com/sitemap_index.xml. Par exemple, dans mon cas, c’est https://geekyhumans.com/sitemap_index.xml.
Une fois que vous ouvrez cette page, vous verrez quelques URL répertoriées sous une forme tabulaire comme celle-ci :
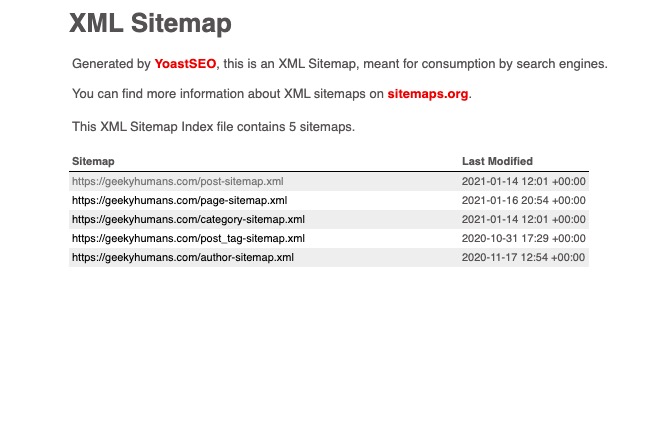
Puisque nous avons besoin de l’URL des articles de blog, nous allons utiliser le post-sitemap. Donc, copiez l’URL du post-sitemap.xml. Dans mon cas, c’est https://geekyhumans.com/post-sitemap.xml.
REMARQUE : Je prends ici l’exemple d’un site Web WordPress, il peut être différent pour d’autres sites Web.
Maintenant, vous savez comment obtenir le plan du site pour vos articles de blog. Concentrons-nous sur notre sujet principal.
Conditions préalables:
- Connaissance de Python
- Compte développeur Twitter avec clés API. (Nous avons déjà expliqué comment obtenir un compte de développeur Twitter ici, vous pouvez le vérifier, puis passer aux étapes suivantes).
Étape -1 : Installation des dépendances
Dans cette étape, nous allons discuter des dépendances et les installer une par une. Voici donc les modules Python que nous utiliserons :
- Twython : C’est une bibliothèque Python qui vous aide à utiliser facilement l’API Twitter. C’est l’une des bibliothèques Python les plus populaires pour Twitter. Il vous permet de tweeter sur Twitter, de rechercher sur Twitter, d’envoyer des messages sur Twitter, de modifier les images de profil et presque tout ce que l’API Twitter est capable de faire. Nous utiliserons cette bibliothèque Python pour tweeter sur Twitter.
- BeautifulSoup : C’est une autre des bibliothèques Python les plus populaires qui vous permet de récupérer des informations à partir de HTML, XML et d’autres langages de balisage. En d’autres termes, vous pouvez dire qu’il vous permet de récupérer des données à partir de pages Web. Nous allons utiliser ce package pour gratter notre sitemap et tweeter automatiquement les articles de blog.
- Requêtes : cette bibliothèque Python est utilisée pour effectuer des requêtes HTTP/HTTPS. Nous utiliserons ce package pour effectuer une requête GET sur notre site Web afin de récupérer des données telles que le titre, la description, etc.
Nous allons utiliser quelques packages supplémentaires, mais ce sont les principaux.
Ouvrez maintenant votre terminal, créez un dossier nommé « twitter-bot » en utilisant la commande ci-dessous puis ouvrez-le :
mkdir twitter-bot
cd twitter-botUne fois dans le dossier, utilisez la commande ci-dessous pour installer les packages :
pip3 install twython
pip3 install beautifulsoup4
pip3 install requestsMaintenant que vous avez enfin installé tous les packages, passons à l’étape suivante.
Étape 2 : Récupération des données du sitemap et du billet de blog
Créez maintenant un fichier twitter.py et collez le code ci-dessous pour importer tous les packages :
from twython import Twython
import requests, json
from bs4 import BeautifulSoup
import re, random Une fois que ce qui précède est fait. Créons une fonction pour récupérer l’URL des articles de blog. Pour ce faire, utilisez le code ci-dessous :
def fetchURL():
xmlDict = []
websites = [ 'https://geekyhumans.com/post-sitemap.xml']
r = requests.get(websites[random.randint(0, len(websites)-1)])
xml = r.text
soup = BeautifulSoup(xml, features="lxml")
sitemapTags = soup.find_all("url")
for sitemap in sitemapTags:
xmlDict.append(sitemap.findNext("loc").text)
return xmlDict[random.randint(0, len(xmlDict))]
Explication des codes :
Nous avons défini une fonction fetchURL() qui fera une requête GET à notre sitemap et la stockera dans une variable r. Puisque r est un objet, nous devons récupérer le texte que nous stockons dans la variable xml.
Après cela, nous utilisons BeautifulSoup pour trouver toutes les balises <url> et les stocker dans un dictionnaire à l’aide d’une boucle.
Maintenant, nous devons également récupérer le titre des URL que nous avons supprimées ci-dessus. Pour ce faire, utilisez la fonction ci-dessous :
def fetchTitle(url):
r = requests.get(url)
xml = r.text
soup = BeautifulSoup(xml)
title = soup.find_all("h1")
return title[0].text
Explication des codes :
We have defined a function `fetchTitle()` wNous avons défini une fonction fetchTitle() qui prend un argument url. Il utilise cette chaîne « url » pour récupérer toutes les données de la page Web. Encore une fois, nous demandons l’URL et, en utilisant BeautifulSoup, nous renvoyons le texte de la balise <h1>.hich takes an argument `url`. It uses that `url` string to fetch all the data from the web page. Again, we’re requesting the URL, and using BeautifulSoup we’re returning the text of the `<h1>` tag.
Voilà, nous en avons fini avec la partie grattage. Définissons maintenant quelques fonctions de Twitter.
Étape -3 : Récupération des hashtags tendance
Non, nous ne récupérons pas les balises qui ont tendance à l’échelle mondiale. Ici, nous utiliserons des balises prédéfinies et, à l’aide de ces balises, nous récupérerons les balises de tendance qui ont été utilisées avec les balises prédéfinies.
Nous devons maintenant créer une autre fonction où nous allons récupérer les balises. Pour ce faire, utilisez le code ci-dessous :
def fetchHashTags():
tags = ['developer', 'API', 'tech', 'ios', 'vscode', 'atom', 'ide', 'javascript', 'php', 'mysql', 'bigdata', 'api']
hashtags = []
search = twitter.search(q='#'+tags[random.randint(0, len(tags)-1)], count=1000)
tweets = search['statuses']
for tweet in tweets :
if tweet['text'].find('#') == 0 :
hashtags += re.findall(r"#(\w+)", tweet['text'])
hashtags = hashtags[:11]
hashtags_string = ' #'.join(hashtags)
return hashtags_stringExplication des codes :
En tant que site Web de programmation / technologie, j’ai utilisé une liste de balises qui se trouvent dans le créneau de la programmation. Après cela, nous avons une liste vide hashtags qui stockera les balises de tendance. Nous utilisons maintenant le package twython pour rechercher les tweets qui utilisent nos balises prédéfinies et les stockons dans la variable tweets.
tweets étant une chaîne, nous devons filtrer les hashtags de la chaîne qui est prise en charge par le paquet re. Alors maintenant, nous avons tous les hashtags sans hachage dans la liste « hashtags ». Ensuite, nous créons simplement une chaîne avec # glue et la renvoyons.
Étape -4 : Publier sur Twitter
Une fois toutes les étapes ci-dessus terminées, collez le code ci-dessous juste après vos instructions d’importation :
APP_KEY = 'TWITTER_API_KEY'
APP_SECRET = 'TWITTER_API_SECRET'
OAUTH_TOKEN = 'OAUTH TOKEN FROM AUTHORIZATION'
OAUTH_TOKEN_SECRET = 'OAUTH TOKEN SECRET FROM AUTHORIZATION'
twitter = Twython(APP_KEY, APP_SECRET, OAUTH_TOKEN, OAUTH_TOKEN_SECRET)Une fois cela fait, essayons de publier sur Twitter. Utilisez le code ci-dessous pour cela :
def postOnTwitter():
url = fetchURL()
title = fetchTitle(url)
hashtags = fetchHashTags()
tweet_string = title + ': ' + url + '\n\n' + hashtags
print(tweet_string)
twitter.update_status(status=tweet_string)
postOnTwitter()Explication des codes :
Nous récupérons simplement tout ce qui est nécessaire pour tweeter, puis créons la chaîne de tweet. Au final, nous transmettons cette chaîne de tweet à la fonction update_status() de Twython.
Le twitter.py final devrait ressembler à ceci :
from twython import Twython
import requests, json
from bs4 import BeautifulSoup
import re, random
APP_KEY = 'TWITTER_API_KEY'
APP_SECRET = 'TWITTER_API_SECRET'
OAUTH_TOKEN = 'OAUTH TOKEN FROM AUTHORIZATION'
OAUTH_TOKEN_SECRET = 'OAUTH TOKEN SECRET FROM AUTHORIZATION'
twitter = Twython(APP_KEY, APP_SECRET, OAUTH_TOKEN, OAUTH_TOKEN_SECRET)
def fetchURL():
xmlDict = []
websites = ['https://nordicapis.com/post-sitemap.xml', 'https://geekyhumans.com/post-sitemap.xml', 'https://www.appcoda.com/post-sitemap.xml']
r = requests.get(websites[random.randint(0, len(websites)-1)])
xml = r.text
soup = BeautifulSoup(xml, features="lxml")
sitemapTags = soup.find_all("url")
for sitemap in sitemapTags:
xmlDict.append(sitemap.findNext("loc").text)
return xmlDict[random.randint(0, len(xmlDict))]
def fetchTitle(url):
r = requests.get(url)
xml = r.text
soup = BeautifulSoup(xml)
title = soup.find_all("h1")
return title[0].text
def fetchHashTags():
tags = ['developer', 'API', 'tech', 'ios', 'vscode', 'atom', 'ide', 'javascript', 'php', 'mysql', 'bigdata', 'api']
hashtags = []
search = twitter.search(q='#'+tags[random.randint(0, len(tags)-1)], count=1000)
tweets = search['statuses']
for tweet in tweets :
if tweet['text'].find('#') == 0 :
hashtags += re.findall(r"#(\w+)", tweet['text'])
hashtags = hashtags[:11]
hashtags_string = ' #'.join(hashtags)
return hashtags_string
def postOnTwitter():
url = fetchURL()
title = fetchTitle(url)
hashtags = fetchHashTags()
tweet_string = title + ': ' + url + '\n\n' + hashtags
print(tweet_string)
twitter.update_status(status=tweet_string)
postOnTwitter()Maintenant, exécutez simplement ce code en utilisant la commande :
python3 twitter.pyC’est ça! Vous avez enfin automatisé vos tweets.
Derniers mots
Auparavant, nous avons expliqué comment créer des tweets sur Twitter à l’aide de Python. Dans cet article, nous avons expliqué comment récupérer les articles de blog d’un site Web et les tweeter. Vous pouvez voir la puissance de Python ou du codage ici. J’ai également créé un cron ici qui récupère les articles de blog de ce site Web et de quelques autres, puis les publie toutes les heures sur Twitter. Cela permet au script de tweeter automatiquement des articles de blog à partir de différents sites Web.
Voici quelques tutoriels utiles que vous pouvez lire :