

Big data tools are the one that can handle high-volume, high-velocity, and/or high-variety information assets that require cost-effective, innovative forms of information processing that enable increased insight, decision-making, and process automation.
Hadoop
The Hadoop is a big data tool that allows for the distributed processing of large data sets across multiple computers using simple programming models. It is developed to scale up from single servers to thousands of machines, each offering local computation and storage.
Rather than rely on hardware to provide high-availability, the library itself is developed to detect and handle failures at the application layer, so providing a highly-available service on top of multiple computers, each of which may be prone to failures.
Key Features of Hadoop
- Hadoop is an open-source tool.
- This tool is compatible with all the platforms.
- It makes data processing flexible.
- It provides efficient data processing.
Qubole

Qubole data service is an independent and all-inclusive Big data platform that manages, learns and optimizes on its own from your usage. This lets the data team concentrate on business outcomes instead of managing the platform.
Out of the many, few famous names that use Qubole are- Warner music group, Adobe, and Gannett. The closest competitor to Qubole is Revulytics.
It comes under a proprietary license that offers business and enterprise edition. The business edition is free of cost and supports up to 5 users.
Key Features of Qubole
- Open-source Engines, optimized for the Cloud.
- Faster time to value.
- Increased flexibility and scale.
- Enhanced adoption of Big data analytics.
- Easy to use.
HPCC

High-Performance Computing Cluster (HPCC) is one of the big data tools, developed by LexisNexis Risk Solution. It runs under the Apache 2.0 license. HPCC offers high redundancy and availability. This could be used for both, Thor cluster and complex data processing. It supports end-to-end big data workflow management.
HPCC maintains code and data encapsulation. It compiles into C++ and native machine code. It is introduced with binary packages supported for Linux distributions and runs on commodity hardware. It can build graphical execution plans.
Key Features of HPCC
- High redundancy.
- Can be used for complex data processing.
- Enhanced scalability and performance.
- Helps to build graphical execution plans.
- This is one of the big data tools that compile into C++ and native machine code.
Cassandra
The Apache Cassandra database is the best choice when you need scalability and high availability without compromising performance. Linear scalability and proven fault-tolerance on commodity hardware or cloud infrastructure make it the best platform for mission-critical data.
Cassandra’s support for replicating across several datacenters is best-in-class, providing lower latency for your users and the peace of mind of knowing that you can survive regional outages.
Key Features of Cassandra
- Continuous availability as a data source.
- This data analysis tool enhances scalability and performance.
- Across the data centres easy distribution of data.
- Data is automatically replicated to various nodes for fault-tolerance.
- It is used by Netflix, Urban Airship, Twitter, Reddit, Constant Contact, Digg, and Cisco.
MongoDB
MongoDB is a NoSQL, document-oriented database written in C, C++, and JavaScript. It is free to use and is one of the best open-source big data tools that supports multiple operating systems including Windows Vista ( and later versions), OS X (10.7 and later versions), Linux, Solaris, and FreeBSD.
Its main features include Aggregation, Adhoc-queries, Uses BSON format, Sharding, Indexing, Replication, Server-side execution of javascript, Schemaless, Capped collection, MongoDB management service (MMS), load balancing and file storage.
Some of the major customers using MongoDB include Facebook, eBay, MetLife, Google, etc.
Key Features of MongoDB
- MongoDB is free to use.
- It is easy to Learn.
- Provides support for multiple technologies and platforms
- It provides flexibility in a cloud-based infrastructure.
- MongoDB stores data using JSON- like documents.
Apache Storm
Apache Storm is a free, open-source distributed real-time framework, offering a fault-tolerant processing system for the unbounded data stream. This computation system supports multiple programming languages. Parallel Calculations are used by this tool, which runs across the cluster of machines.
This big data tool has a fail fast, auto-restart, approach, in case a node dies. Storm supports the Direct Acrylic Graph Topology. It is surely the easiest tool for Bigdata Analysis, once deployed. It can interoperate with Hadoop’s HDFS through adapters if required, which is another positive point to make it one of the useful open source big data tools.
Key Features of Apache Storm
- It is very fast and fault-tolerant.
- Apache Storm is easy to use.
- The language of the Apache storm is written on Clojure
- This big data tool supports multiple languages.
- Guarantees the processing of data.
CouchDB
Apache CouchDB is an open-source, cross-platform introduced in the year 2005. It is a document-oriented NoSQL database that aims at ease of use and holding a scalable architecture. It is written in concurrency-oriented language Erlang.
Key Features of CouchDB
- It is compatible with platforms, i.e., Windows, Linux, Mac-ios, etc.
- It is a single node database.
- Easy interface for document insertion, updates, retrieval, and deletion
- JSON-based document format can be translatable across different languages
- Runs on any number of servers.
Statwing
Statwing is an easy-to-use and efficient data science as well as a statical tool. It was developed for big data analysts, business users, and market researchers. The modern interface of this can do any statistical operation automatically.
Key features of Statwing
- It explores any data in seconds.
- It is an easy-to-use statistical tool.
- Its starting price is $50.00/month/user. A free trial is also available.
- It helps to clean data, explore relationships, and create charts in minutes.
- It can translate the outcomes into plain English text.
Flink
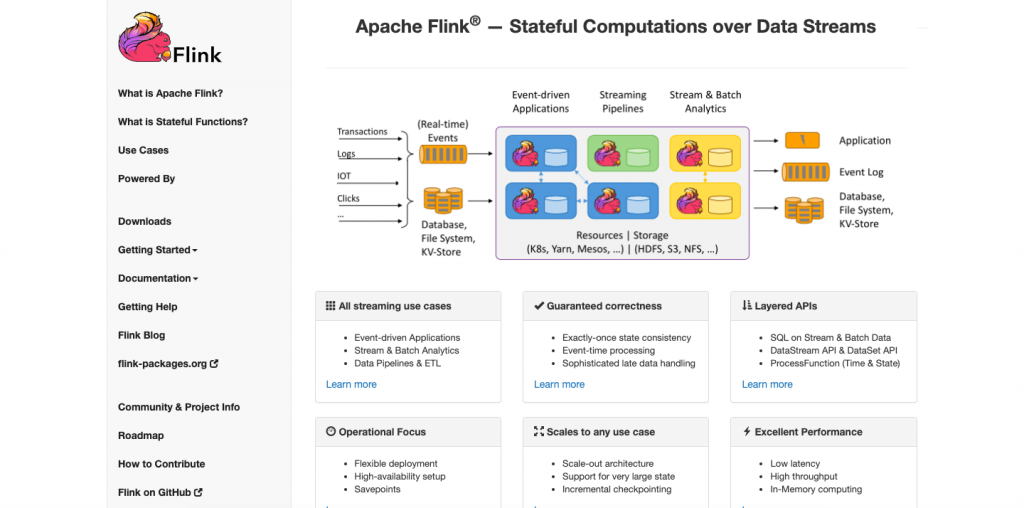
Apache Flink is a tool and distributed processing engine for stateful computations over unbounded and bounded data streams. Flink has been developed to run in all common cluster environments, perform computations at in-memory speed and any scale.
Apache Flink provides a high-throughput, low-latency streaming engine as well as support for event-time processing and state management.
Flink apps are fault-tolerant in the event of machine failure and support exactly-once semantics. Programs can be written in any of the languages- Java, Scala, Python, and SQL and are automatically compiled and optimized into dataflow programs that are executed in a cluster or cloud environment.
It does not provide its own data storage system, but provides data source and sink connectors to systems like Amazon Kinesis, Apache Kafka, Alluxio, HDFS, Apache Cassandra, and ElasticSearch.
Key Features of Flink
- Apache Flink is an open-source, cross-platform.
- Can easily recover from failures
- Flink allows flexible windowing.
- This is written in Java and Scala.
- It is fault-tolerant, scalable, and high-performing.
Pentaho
Although this name tends to be associated with a sweet dream of a 17-year-old hacker, this tool provides you a bit different but significant things. Pentaho combines both analytic processing and data integration that makes attaining results quicker. What is more, its built-in integration with IoT endpoints and unique metadata injection functionality speeds data collection from multiple sources.
Overall, this tool is good at data access and integration for effective data visualization. It empowers users to build big data at the source and streams them for accurate analytics. Pentaho allows checking data with easy access to analytics, including charts, visualizations, and reporting. Plus, it supports a wide spectrum of big data sources by offering unique capabilities.
Key Features of Pentaho
- Data access and integration for effective data visualization.
- It offers real-time data processing to boost digital insights.
- It supports a wide range of big data sources.
- Coding is not required in this tool.
- It supports a wide spectrum of big data sources by offering unique capabilities.
Hive

Hive is an open-source ETL(extraction, transformation, and load) and data warehousing tool. It is developed over the HDFS. It can perform several operations effortlessly like data encapsulation, ad-hoc queries, and analysis of massive datasets. For data retrieval, it applies the partition and bucket concept.
Key Features of Hive
- It supports SQL for Data Modelling
- It is OS Independent.
- It Supports SQL for data modelling and interaction.
- Allows defining the tasks using JAVA or python.
RapidMiner
RapidMiner is a free open-source environment for predictive analytics that has a full arsenal of necessary functions. The system supports all stages of in-depth data analysis, including the resulting visualization, validation, and optimization.
To use RapidMiner, you do not need to know to program. Here the principle of visual programming is implemented. You do not need to write code as well as you do not need to carry out complex mathematical calculations.
Key Features of RapidMiner
- It is a leading open-source system for text and data mining.
- Rapid Miner uses both GUI processing.
- It allows multiple data management to its users.
- Generates interactive and shareable dashboards
- Processing based on Remote analysis.
Check out best 13 Data mining algorithms that you can use.
Cloudera
Speaking of which, Cloudera is essentially a brand name for Hadoop with some extra services added on. They can help your business build an enterprise data hub to grant better access to stored data to those in your organization.
While it does have an open-source element, Cloudera is mostly an enterprise solution to help businesses manage their Hadoop ecosystem. Essentially, they do a lot of the hard work of administering Hadoop for you. They will also deliver a specific amount of data security, which is very important if you are storing any sensitive or personal data.
Key Features of Cloudera
- Unbelievable performance analytics.
- High security and governance.
- Can manage Cloudera enterprise across AWS.
- Delivers real-time insights.
- Cloudera Manager administers the Hadoop cluster very well.
DataCleaner

The data profiling engine, DataCleaner, is used to discovering and analyzing the quality of data. It has some splendid features like supports HDFS datastores, fixed-width mainframe, duplicate detection, data quality ecosystem, and so forth. You can use its 30 days of the free trial.
Key Features of DataCleaner
- Interactive and explorative data profiling feature.
- Detects fuzzy records.
- It has user-friendly and explorative data profiling.
- Validates data and reports them.
- Use of reference to clean the data.
OpenRefine
OpenRefine (formerly GoogleRefine) is one of the best open-source big data tools that is dedicated to cleaning messy data. You can explore huge data sets quickly and easily, even if the data from your business is a little unstructured.
As far as big data analytics software goes, OpenRefine is pretty user-friendly. Though, a good knowledge of data cleaning principles certainly helps you get the most out of it. The nice thing about OpenRefine is that it has a huge community with lots of contributors. This means that the analytics software is constantly improving, and the helpful/patient community can answer questions whenever you get stuck.
Key Features of OpenRefine
- It helps to explore large data sets easily.
- Can import various formats of data.
- Take just milliseconds to explore datasets.
- It can perform advanced data operations using Refine Expression Language.
- Make the instantaneous link between data sets.
Talend
It is an open-source integration software designed to turn data into insights. It provides various services and software, including cloud storage, enterprise application integration, data management, etc. Backed by a vast community, it allows all Talend users and members to share information, experiences, doubts from any location.
Key Features of Talent
- Streamlines ETL and ELT for Big data.
- Accomplish the speed and scale of spark.
- Accelerates your move to real-time.
- Handles multiple data sources.
- It permits Open Studio.
Apache SAMOA
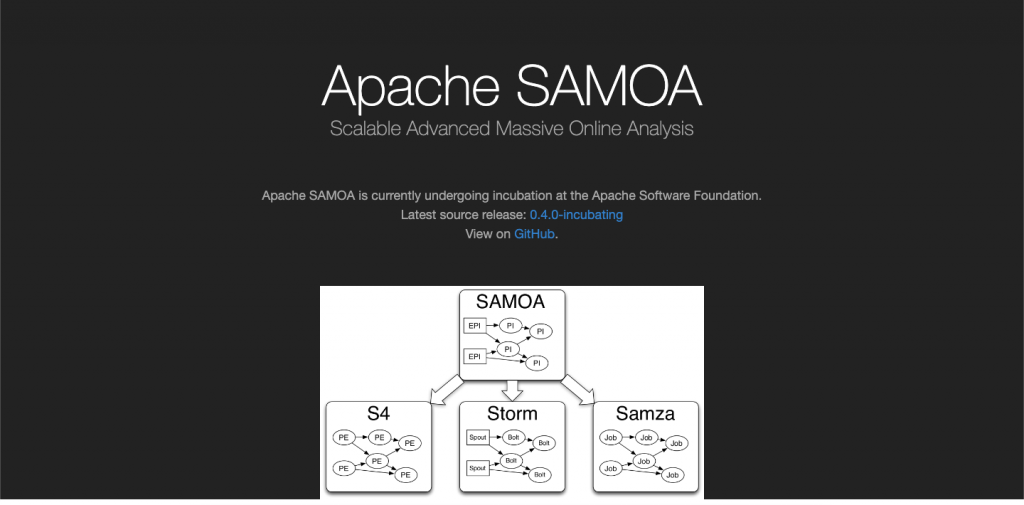
Apache SAMOA is a well-known open-source big data tools. Apache SAMOA is used for distributed streaming algorithms for big data mining. It has got immense importance in the industry, as it could be programmed and run everywhere. It does not need any complex backup or update process.
SAMOA’s existing infrastructure is reusable, and the deploying cycles could be avoided. Not only for data mining, but it is also used for other machine learning tasks like clustering, regression, classification, programming abstractions for new algorithms, etc.
Key Features of Apache SAMOA
- The Program can be run everywhere.
- Simple and fun to use.
- Fast and scalable.
- True real-time streaming.
- There is no system downtime in this Apache SAMOA.
Neo4j
Neo4j is an open-source tool widely used graph database in the big data industry. It follows the fundamental structure of the graph database, which is inter-connected node-relationship of data.
It supports the ACID transaction. It provides highly scalable and reliable performance. It is flexible as it does not need a schema or data type to store data. Neo4j can be integrated with other databases. It maintains a key-value pattern in data storing. It supports query language for graphs which is known as Cypher.
Key Features of Neo4j
- Neo4j provides scalability, high-availability, and flexibility.
- It provides high availability to its users.
- It can integrate with other databases
- The ACID transaction is supported by this big data tool.
- Supports query language for graphs which is commonly known as Cypher.
Teradata

If you need big data tools for developing large scale data warehousing applications, then, the well known relational database management system, Teradata is the best option. This system offers end-to-end solutions for data warehousing. It is developed based on the MPP (Massively Parallel Processing) Architecture. The significant components are a node, parsing engine, the message passing layer, and the access module processor (AMP).
Key Features of Teradata
- It provides data warehousing products and services.
- It is highly scalable.
- Teradata supports industry-standard SQL to interact with the data.
Tableau
Tableau is a software solution for business intelligence and analytics which presents a variety of integrated products that aid the world’s largest organizations in visualizing and understanding their data.
The software contains three main products i.e.Tableau Desktop (for the analyst), Tableau Server (for the enterprise), and Tableau Online (to the cloud). Also, Tableau Reader and Tableau Public are the two more products that have been recently added.
Tableau is capable of handling all data sizes and is easy to get to for technical and non-technical customer base and it gives you real-time customized dashboards. It is one of the greatest big data tools for data visualization and exploration.
Out of the many, some famous names that use Tableau are – Verizon Communications, ZS Associates, and Grant Thornton.
Key Features of Tableau
- Data blending capabilities of this big data tool are just awesome.
- Real-time collaboration is available.
- Out of the box support for connection with most of the databases.
- No-code data queries.
- Mobile-ready, interactive and shareable dashboards.