

Eine RDF-Anweisung drückt eine Beziehung zwischen zwei Ressourcen aus. Das Subjekt und das Objekt stellen die beiden Ressourcen dar, die miteinander in Beziehung stehen; das Prädikat repräsentiert die Art ihrer Beziehung. Die Beziehung ist gerichtet formuliert (von Subjekt zu Objekt) und wird als RDF-Eigenschaft bezeichnet. RDF ermöglicht es uns, viel mehr als nur Worte zu kommunizieren; Es ermöglicht uns, Daten zu kommunizieren, die sowohl von Maschinen als auch von Menschen verstanden werden können. In diesem Tutorial führen wir die RDF-Verarbeitung in Python mit RDFLib durch.
Im Zusammenhang mit dem Datenaustausch im Internet ist RDF ein Modell zur Datenrepräsentation. RDF-Beschreibungen sind jedoch nicht dafür ausgelegt, im Web angezeigt zu werden. Es ermöglicht verschiedenen Systemen, Daten und Metadaten gemeinsam zu nutzen, sodass die Daten besser interoperabel werden. Viele verwenden das RDF, um Details einer Website zu beschreiben. Obwohl RDF Ihnen keine Tools zum Abfragen der Daten bietet, kann es dennoch nützlich sein, wenn Sie sie nur zwischen Systemen teilen oder speichern möchten, und genau das werden wir in diesem Tutorial tun. Für diesen Blog verwenden wir die RDFLib.
Voraussetzungen
Für die RDF-Verarbeitung in Python müssen Sie RDFLib einfach mit Pythons Paketverwaltungstool pip installieren:
pip install rdflibOder wenn Sie die neueste Version installieren möchten, können Sie den Master-Zweig ihres GitHub-Repos klonen:
git clone https://github.com/RDFLib/rdflib.gitWie funktioniert es?
RDFLib verwendet Graphen, um hierin Daten zu speichern. Diese Graphen bestehen am häufigsten aus Tupeln mit drei Elementen, die als „Triples“ bekannt sind. RDF ermöglicht es uns, Aussagen über Ressourcen zu machen. Eine Anweisung hat immer folgenden Aufbau:
<subject> <predicate> <object>.
Auf Graphen kann mit den zugehörigen Methoden von RDFLib (z. B. add() zum Hinzufügen von Tripeln) zugegriffen werden, die generische Funktionen zum Platzieren von Tripeln über einen Begriff bereitstellen, der als RDFS bezeichnet wird (wie in der RDF-Syntax). Zusätzlich zu diesen Set-Operationen und Suchmethoden wurden bestimmte eingebaute Python-Methoden neu definiert: Sie imitieren Containertypen und verhalten sich auf vorhersagbare Weise, also stellen Sie sie sich eher wie eine Menge von Tupeln mit drei Elementen vor.
[
(subject0, predicate0, object0),
(subject1, predicate1, object1),
...
(subjectN, predicateN, objectN)
]Das Subjekt, das Objekt und alle Fakten über ein Tripel bilden das, was in der relationalen Algebra als Knoten bezeichnet wird. Ein RDF-Diagramm kann URIs mit unterschiedlichen Eigenschaften wie http://example.com/product oder auch leere Knoten, „BNode“, enthalten, die für URI-Referenzen gekennzeichnet sind, die eigentlich keine Ressource selbst referenzieren. Neben leeren Knoten kann der Graph Literale enthalten, die nur Dinge sind, die im Graphen ausgedrückt werden, wie z. B. Zeichenfolgen oder ganze Zahlen.
Erstellen eines RDF-Diagramms
Ok, jetzt erstellen wir ein Beispiel für ein Diagramm, um einige der RDFLib-Funktionen zu demonstrieren:
# Import the requirements modules
from rdflib import URIRef, BNode, Literal, Namespace
from rdflib.namespace import FOAF, DCTERMS, XSD, RDF, SDO
# first of all we want to define the nodes
# since we know their exact URI
# we want to use the URIRef reference class
mona_lisa = URIRef('http://www.wikidata.org/entity/Q12418')
davinci = URIRef('http://dbpedia.org/resource/Leonardo_da_Vinci')
lajoconde = URIRef('http://data.europeana.eu/item/04802/243FA8618938F4117025F17A8B813C5F9AA4D619')
# similarly, if we don't want to define the entire URI
# we can create namespaces
EX = Namespace('http://example.org/')
# then we can create nades to specify the namespace
# and put the name of the entity
bob = EX['Bob']
alice = EX['Alice']
# we can also create literal values to specify some details we wanted
birth_date = Literal("1990-07-04", datatype=XSD['date'])
title = Literal('Mona Lisa', lang='en')Wir können einige Überprüfungen vornehmen, obwohl es noch nicht vollständig ist. Mögen
print (title)
print (title.lang)
etc.Als Nächstes beginnen wir tatsächlich mit der Erstellung eines Diagramms und fügen alle Details hinzu:
# first import the graph
# then initialize it
from rdflib import Graph
g = Graph()
# Bind prefix to namespace to make it more readable
g.bind('ex', EX)
g.bind('foaf', FOAF)
g.bind('schema', SDO)
g.bind('dcterms', DCTERMS)Danach können wir damit beginnen, eine Reihe von Tripeln innerhalb des Diagramms hinzuzufügen. Wir können es also mit der Methode add () tun, die Tupel in Form von 3 Elementen annimmt. Das heißt, das erste Element ist das Subjekt, das zweite das Prädikat oder die Eigenschaft und das letzte das Objekt.
g.add((bob, RDF.type, FOAF.Person))
g.add((bob, FOAF.knows, alice))
g.add((bob, FOAF['topic_interest'], mona_lisa))
g.add((bob, SDO['birthDate'], birth_date))
g.add((mona_lisa, DCTERMS['creator'], davinci))
g.add((mona_lisa, DCTERMS['title'], title))
g.add((lajoconde, DCTERMS['subject'], mona_lisa))Und jetzt werfen wir einen Blick auf den Graphen, indem wir ihn serialisieren:
print(g.serialize(format='ttl'))Führen Sie diese Datei nun wie jede andere Python-Datei aus:
python3 test.py
#or
python test.pyUnd Sie sollten ein Ergebnis wie dieses erhalten:
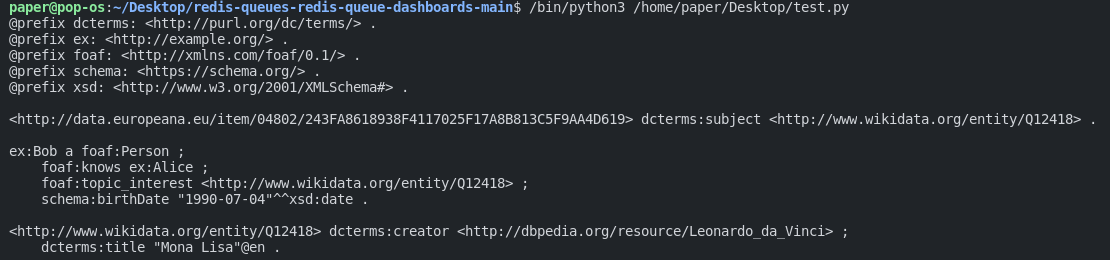
So sieht es im Turtle-Format aus, wir können es auch in XML umwandeln. Ändern Sie einfach die letzte Druckzeile mit:
print(g.serialize(format='xml'))Nun, hier haben wir das Ergebnis in einer sehr einfachen Form gedruckt, wir verwenden dieses Ergebnis auch in einer Art Datenbankformat, zum Beispiel:
for prefix, ns in g.namespaces():
print(prefix, ns)Wir können die zuvor definierten Präxine durchlaufen. Dies gibt ein Ergebnis wie dieses aus:
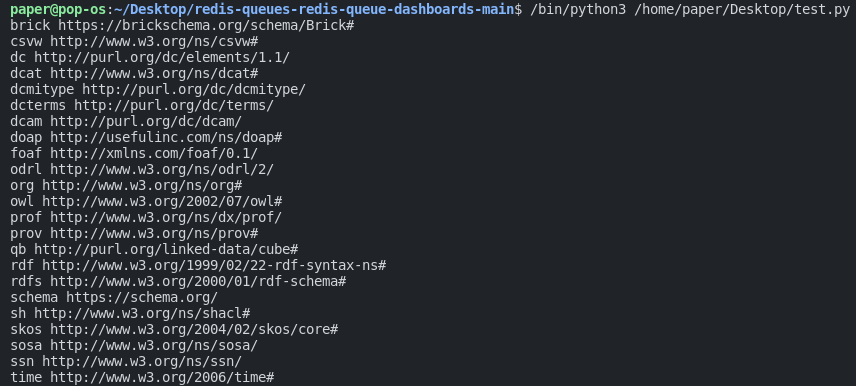
Dies sind die uns zur Verfügung gestellten Präfixe!
Bearbeiten des RDF-Diagramms
Nehmen wir nun an, dass wir einen Fehler gemacht haben und einige Werte in der Grafik bearbeiten möchten. In diesem Fall können wir die set()-Methode verwenden, anstatt sie jedes Mal manuell zu beheben.
g.set((bob, SDO['birthDate'], Literal('1990-01-01', datatype=XSD.date)))
g.set((mona_lisa, DCTERMS['title'], Literal('La Joconde', lang='fr')))Hinweis: Auch hier übergeben wir wieder die drei Elemente, das erste Element ist das Subjekt, das zweite das Prädikat und das dritte das Objekt.
In diesem Fall haben wir beispielsweise den Geburtstag von Bob auf den 1. Januar 1990 geändert, und wir möchten auch den Titel von monalisa ändern, um einen anderen Titel zu haben, und wir möchten auch die Sprache dieser Zeichenfolge ändern. Lassen Sie uns das also ausführen und Sie sollten einen Unterschied in den Ergebnissen sehen:
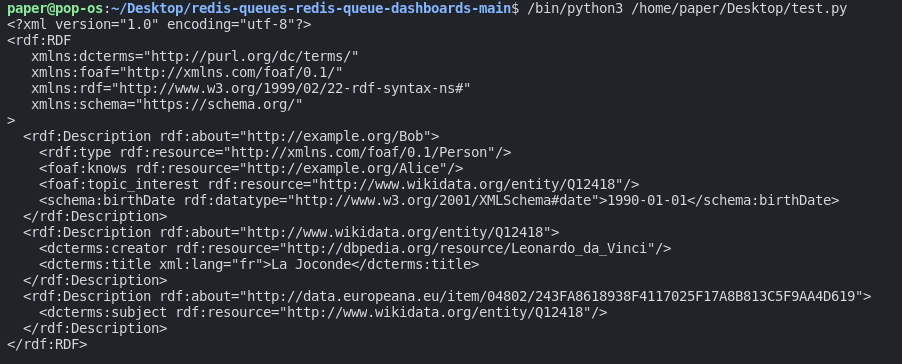
Und das ist es, Sie können die Änderungen hier sehen.
Eine letzte Sache, wenn Sie eine Variable aus dem Diagramm entfernen möchten, können Sie die Methode remove () verwenden, die wieder ein Tupel mit den drei Elementen verwendet. Beispiel:
g.remove((mona_lisa, None, None))Dies würde jedes Tupel leeren, das Sie darin einfügen können.
der Abschluss
Wir hoffen, dass Ihnen dieser Blogbeitrag zur Verwendung von RDF in Python gefallen hat. Wenn Sie mehr über die Verwendung von RDF erfahren möchten, können Sie die Dokumentation von RDFLib lesen, um mehr über die Verwendung der Bibliothek zu erfahren. Außerdem können Sie auf der GitHub-Seite mehr über die Verwendung der RDFLib erfahren.
Hier sind einige nützliche Tutorials, die Sie lesen können:
- Echtzeit-Zwischenflussschätzung für die Videoframe-Interpolation mit Python
- Extrahieren Sie gespeicherte Chrome-Passwörter und entschlüsseln Sie sie mit Python
- Vergleichen Sie zwei Bilder und markieren Sie Unterschiede mit Python
- Generieren von QR-Codes und Barcodes in Python
- Emotionserkennung mit Python
- Python-Programm zum Erstellen von Blockchain und Mining
- Wetterinformationen mit Python abrufen
- Erstellen Sie eine News-Aggregator-Site mit Python
- Erstellen Sie einen Websocket-Server mit Python und Tornado