

An RDF statement expresses a relationship between two resources. The subject and the object represent the two resources being related; the predicate represents the nature of their relationship. The relationship is phrased in a directional way (from subject to object) and is called an RDF property. RDF allows us to communicate much more than just words; it allows us to communicate data that can be understood by machines as well as people. In this tutorial, we’ll do the RDF Processing in Python with RDFLib.
In the context of exchanging data on the internet, RDF is a model for data representation. Although RDF descriptions are not designed to be displayed on the web. It allows different systems to share data and metadata so that the data becomes more interoperable. Many use the RDF for describing details of a website. While RDF doesn’t give you any tools for querying the data, it still can be useful if you just want to share or store it between systems and that’s what we’ll do in this tutorial. For the purpose of this blog, we are going to use the RDFLib.
Prerequisites
For RDF Processing in Python, you need to install RDFLib simply using Python’s package management tool pip:
pip install rdflibOr if you want to install the latest version, you can clone the master branch of their GitHub repo:
git clone https://github.com/RDFLib/rdflib.gitHow does it work
RDFLib uses graphs to store data herein. These graphs are most commonly composed of three-item tuples known as “triples”, RDF allows us to make statements about resources. A statement always has the following structure:\ <subject> <predicate> <object>.
Graphs can be accessed using RDFLib’s associate methods (e.g. add() for adding triples) that expose generic functions for placing triples about a notion that is referred to as RDFS (as in RDF Syntax). In addition to these set operations and search methods, certain built-in Python methods have been redefined: they imitate container types and behave in a predictable manner so think of them more like a set of 3-item tuples.
[
(subject0, predicate0, object0),
(subject1, predicate1, object1),
...
(subjectN, predicateN, objectN)
]The subject, object, and all facts about a triple make up what’s referred to in relational algebra as a node. An RDF Graph can contain URIs with different properties like http://example.com/product or it can also contain blank nodes, “BNode” that are labeled for URI references that do not actually reference any resource on their own. As well as blank nodes, the graph may have literals which are just things that are expressed in the graph such as strings or integers.
Creating a RDF Graph
Ok, so now let’s create an example of a Graph to showcase some of RDFLib’s features:
# Import the requirements modules
from rdflib import URIRef, BNode, Literal, Namespace
from rdflib.namespace import FOAF, DCTERMS, XSD, RDF, SDO
# first of all we want to define the nodes
# since we know their exact URI
# we want to use the URIRef reference class
mona_lisa = URIRef('http://www.wikidata.org/entity/Q12418')
davinci = URIRef('http://dbpedia.org/resource/Leonardo_da_Vinci')
lajoconde = URIRef('http://data.europeana.eu/item/04802/243FA8618938F4117025F17A8B813C5F9AA4D619')
# similarly, if we don't want to define the entire URI
# we can create namespaces
EX = Namespace('http://example.org/')
# then we can create nades to specify the namespace
# and put the name of the entity
bob = EX['Bob']
alice = EX['Alice']
# we can also create literal values to specify some details we wanted
birth_date = Literal("1990-07-04", datatype=XSD['date'])
title = Literal('Mona Lisa', lang='en')We can make some checks on it though it is not complete yet. Like
print (title)
print (title.lang)
etc.Next, let’s actually start creating a graph and add all the details:
# first import the graph
# then initialize it
from rdflib import Graph
g = Graph()
# Bind prefix to namespace to make it more readable
g.bind('ex', EX)
g.bind('foaf', FOAF)
g.bind('schema', SDO)
g.bind('dcterms', DCTERMS)After this, we can start adding a set of triples inside the graph. So we can do it with the add() method which takes tuples of the form of 3 elements. That is, the first element is the subject, the second is the predicate or the property and the last is the object.
g.add((bob, RDF.type, FOAF.Person))
g.add((bob, FOAF.knows, alice))
g.add((bob, FOAF['topic_interest'], mona_lisa))
g.add((bob, SDO['birthDate'], birth_date))
g.add((mona_lisa, DCTERMS['creator'], davinci))
g.add((mona_lisa, DCTERMS['title'], title))
g.add((lajoconde, DCTERMS['subject'], mona_lisa))And now let’s take a look at the graph by serializing it:
print(g.serialize(format='ttl'))Now run this file as you would any other python file:
python3 test.py
#or
python test.pyAnd you should get a result like this:
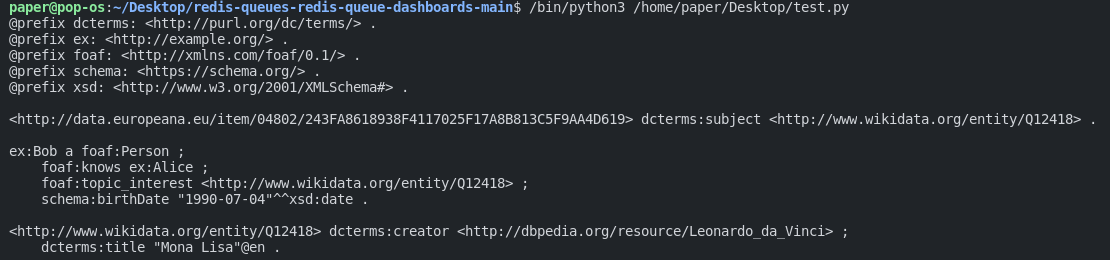
This is how it looks in the turtle format, we can also change it to XML. Just change the last, print line with:
print(g.serialize(format='xml'))Now, here we have printed the result in a very simple form, we also use this result in the kind of like database format, for example:
for prefix, ns in g.namespaces():
print(prefix, ns)We can loop over the prexines that we defined earlier. This print a result like this:
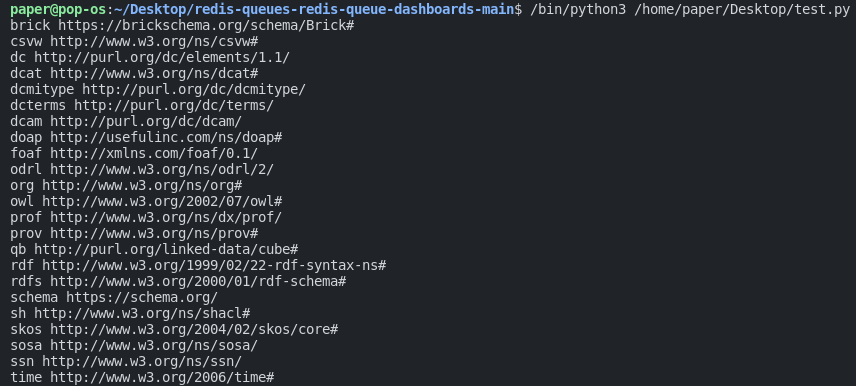
These are the prefixes made available to us!
Editing the RDF Graph
Now, let’s say that we made a mistake and want to edit out some values in the graph. In this case, we can use the set() method instead of manually going in each time to fix it.
g.set((bob, SDO['birthDate'], Literal('1990-01-01', datatype=XSD.date)))
g.set((mona_lisa, DCTERMS['title'], Literal('La Joconde', lang='fr')))Note: Here again, we are passing the three elements again, the first element is the subject, the second is the predicate and the third is the object.
So, for example in this case we ate changing the birthday of Bob to be the first of January of 1990 and we also want to change the title of monalisa to have a different title and we also want to change the language of this string. So let’s run this and you should see a difference in the results:
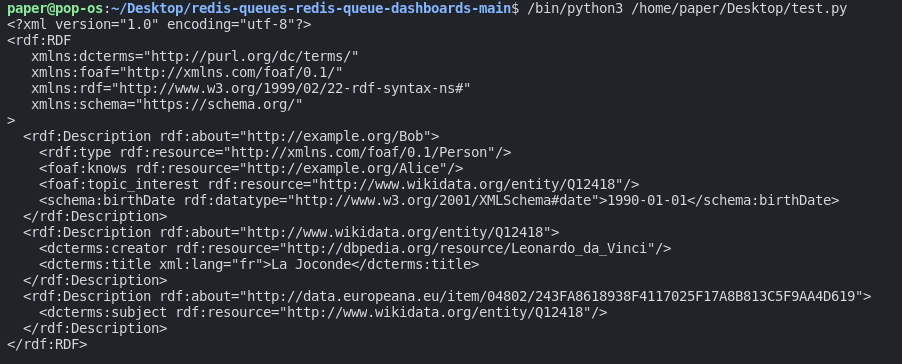
And that’s it, you can see the changes here.
One last thing, if you want to remove some variable from the graph, you can use the remove() method which is going to take a tuple containing the three elements again. Example:
g.remove((mona_lisa, None, None))This would empty out any tuple that you may put into it.
Conclusion
We hope you enjoyed this blog post on how to use RDF in Python. If you are interested in learning more about how to use RDF, you can read RDFLib’s documentation to learn more about how to use the library. Also, you can learn more about how to use the RDFLib on its GitHub page.
Here are some useful tutorials that you can read: