

In this tutorial, I am gonna show you how you can create a script that will scrape the data from your blog’s sitemap and tweet blog posts on Twitter automatically. So there are a lot of paid services that offer this feature like HootSuite. What if you could do the same for free?
The web scraper will scrape data like the URL of the post, title of the article, and one-liner description of that blog post. Most of the data we can fetch from the sitemap of our website.
What is Sitemap and How to find it?
Let me explain it to you, a sitemap is an XML page that stores all your metadata of your blog posts. It stores data like the URL of the published articles, the last modified time, and the number of images.
You might be wondering why we need a sitemap right?
The sitemap is needed so that search engines can list your blog posts or any page being published on your website as soon as possible. There are other reasons too, you can check this article for more information.
Now let’s try to find the sitemap of your website. In most cases, it’s www.YOUR-WEBSITE.com/sitemap.xml or www.YOUR-WEBSITE.com/sitemap_index.xml. For example, in my case it’s https://geekyhumans.com/sitemap_index.xml.
Once you open that page, you’ll see few URLs listed in a tabular form like this:
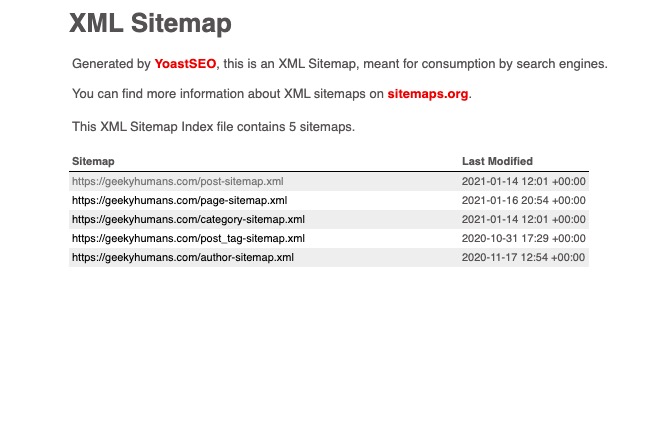
Since we need the URL of blog posts, we’ll go with post-sitemap. So, copy the URL of the post-sitemap.xml. In my case it’s https://geekyhumans.com/post-sitemap.xml.
NOTE: I am taking the example of a WordPress website here, it may be different for other websites.
Now, you know how you can get the sitemap for your blog posts. Let’s focus on our main topic.
Prerequisites:
- Knowledge of Python
- Twitter developer account with API keys. (We have already covered how to get Twitter Developer Account here, you can check it out and then continue with the next steps).
Step -1: Installing dependencies
In this step, we’ll discuss the dependencies and install them one by one. So these are the Python modules that we’ll use:
- Twython: It is a Python library that helps you to use Twitter API easily. It is one of the most popular Python libraries for Twitter. It lets you tweet on Twitter, search on Twitter, message on Twitter, change profile images, and almost everything that Twitter API is capable of doing. We’ll be using this Python library to tweet on Twitter.
- BeautifulSoup: This is another one of the most popular Python libraries which lets you fetch information from HTML, XML, and other markup languages. In other words, you can say that it lets you scrape data from web pages. We are going to use this package to scrape our sitemap and tweet blog posts automatically.
- Requests: This Python library is used to make HTTP/HTTPS requests. We will use this package to make a GET request on our website to fetch data like title, description, etc.
We are going to use a few more packages but these are the major ones.
Now open your terminal, create a folder named “twitter-bot” using the below command and then open it:
mkdir twitter-bot
cd twitter-botOnce you’re in the folder use the below command to install the packages:
pip3 install twython
pip3 install beautifulsoup4
pip3 install requestsNow you have finally installed all the packages, let’s move towards the next step.
Step -2: Fetching data from sitemap and the blog post
Now create a file `twitter.py` and paste the below code to import all the packages:
from twython import Twython
import requests, json
from bs4 import BeautifulSoup
import re, random Once the above is done. Let’s create a function to fetch the URL of blog posts. To do so use the below code:
def fetchURL():
xmlDict = []
websites = [ 'https://geekyhumans.com/post-sitemap.xml']
r = requests.get(websites[random.randint(0, len(websites)-1)])
xml = r.text
soup = BeautifulSoup(xml, features="lxml")
sitemapTags = soup.find_all("url")
for sitemap in sitemapTags:
xmlDict.append(sitemap.findNext("loc").text)
return xmlDict[random.randint(0, len(xmlDict))]
Code Explanation:
We have defined a function `fetchURL()` which will make a `GET` request to our sitemap and store it in a variable `r`. Since `r` is an object, we need to get the text which we are storing in the variable `xml`.
After that, we’re using BeautifulSoup to find all the `<url>` tags and store them in a dictionary using a loop.
Now we also have to fetch the title of the URLs which we have scrapped above. To do so, use the below function:
def fetchTitle(url):
r = requests.get(url)
xml = r.text
soup = BeautifulSoup(xml)
title = soup.find_all("h1")
return title[0].text
Code Explanation:
We have defined a function `fetchTitle()` which takes an argument `url`. It uses that `url` string to fetch all the data from the web page. Again, we’re requesting the URL, and using BeautifulSoup we’re returning the text of the `<h1>` tag.
That’s it we are done with the scraping part. Now let’s define some Twitter functions.
Step -3: Fetching the trending hashtags
No, we are not fetching the tags which are globally trending. Here we’ll be using some predefined tags and using those tags we’ll be fetching the trending tags which were used with the predefined tags.
Now we have to create one more function where we’ll be fetching the tags. To do so, use the below code:
def fetchHashTags():
tags = ['developer', 'API', 'tech', 'ios', 'vscode', 'atom', 'ide', 'javascript', 'php', 'mysql', 'bigdata', 'api']
hashtags = []
search = twitter.search(q='#'+tags[random.randint(0, len(tags)-1)], count=1000)
tweets = search['statuses']
for tweet in tweets :
if tweet['text'].find('#') == 0 :
hashtags += re.findall(r"#(\w+)", tweet['text'])
hashtags = hashtags[:11]
hashtags_string = ' #'.join(hashtags)
return hashtags_stringCode Explanation:
Being a programming/tech website, I have used a list of tags that are in the programming niche. After that, we have got an empty list `hashtags` which will store the trending tags. Now we’re using the `twython` package to search for the tweets which are using our predefined tags and store them in `tweets` variable.
`tweets` being a string, we have to filter out the hashtags from the string which is being taken care of by the `re` package. So now We have got all the hashtags without a hash in the list `hashtags`. Next, we’re just creating a string with `#` glue and return it.
Step -4: Posting on Twitter
Once all the above steps are done, paste the below code right after your import statements:
APP_KEY = 'TWITTER_API_KEY'
APP_SECRET = 'TWITTER_API_SECRET'
OAUTH_TOKEN = 'OAUTH TOKEN FROM AUTHORIZATION'
OAUTH_TOKEN_SECRET = 'OAUTH TOKEN SECRET FROM AUTHORIZATION'
twitter = Twython(APP_KEY, APP_SECRET, OAUTH_TOKEN, OAUTH_TOKEN_SECRET)Once done, let’s try to post on Twitter. Use the below code for this:
def postOnTwitter():
url = fetchURL()
title = fetchTitle(url)
hashtags = fetchHashTags()
tweet_string = title + ': ' + url + '\n\n' + hashtags
print(tweet_string)
twitter.update_status(status=tweet_string)
postOnTwitter()Code Explanation:
We’re just fetching everything which is needed to tweet and then creating the tweet string. In the end, we’re passing that tweet string to the `update_status()` function of Twython.
The final `twitter.py` should look something like this:
from twython import Twython
import requests, json
from bs4 import BeautifulSoup
import re, random
APP_KEY = 'TWITTER_API_KEY'
APP_SECRET = 'TWITTER_API_SECRET'
OAUTH_TOKEN = 'OAUTH TOKEN FROM AUTHORIZATION'
OAUTH_TOKEN_SECRET = 'OAUTH TOKEN SECRET FROM AUTHORIZATION'
twitter = Twython(APP_KEY, APP_SECRET, OAUTH_TOKEN, OAUTH_TOKEN_SECRET)
def fetchURL():
xmlDict = []
websites = ['https://nordicapis.com/post-sitemap.xml', 'https://geekyhumans.com/post-sitemap.xml', 'https://www.appcoda.com/post-sitemap.xml']
r = requests.get(websites[random.randint(0, len(websites)-1)])
xml = r.text
soup = BeautifulSoup(xml, features="lxml")
sitemapTags = soup.find_all("url")
for sitemap in sitemapTags:
xmlDict.append(sitemap.findNext("loc").text)
return xmlDict[random.randint(0, len(xmlDict))]
def fetchTitle(url):
r = requests.get(url)
xml = r.text
soup = BeautifulSoup(xml)
title = soup.find_all("h1")
return title[0].text
def fetchHashTags():
tags = ['developer', 'API', 'tech', 'ios', 'vscode', 'atom', 'ide', 'javascript', 'php', 'mysql', 'bigdata', 'api']
hashtags = []
search = twitter.search(q='#'+tags[random.randint(0, len(tags)-1)], count=1000)
tweets = search['statuses']
for tweet in tweets :
if tweet['text'].find('#') == 0 :
hashtags += re.findall(r"#(\w+)", tweet['text'])
hashtags = hashtags[:11]
hashtags_string = ' #'.join(hashtags)
return hashtags_string
def postOnTwitter():
url = fetchURL()
title = fetchTitle(url)
hashtags = fetchHashTags()
tweet_string = title + ': ' + url + '\n\n' + hashtags
print(tweet_string)
twitter.update_status(status=tweet_string)
postOnTwitter()Now just run this code by using the command:
python3 twitter.pyThat’s it! You have finally automated your tweets.
Final Words
Previously we covered how to make tweets on Twitter using Python, in this article we have covered how to scrape blog posts from a website and tweet it. You can see the power of Python or coding here. I have also created a cron here which picks up the blog posts from this website and a few others and then posts every hour on Twitter. This allows the script to tweet blog posts automatically from different websites.